 DEVELOPERS
DEVELOPERSMarch 15, 2026
MetalRT Now Does Speech-to-Speech. 1.52x Faster Than mlx-audio.
MetalRT adds native speech-to-speech support. 1.68s end-to-end latency, 123 tok/s generation throughput, 1.52x faster than mlx-audio on a single M4 Max.
Backed by Y Combinator
Tutorials, demos, and guides for building on-device AI apps
DEVELOPERSMarch 15, 2026
MetalRT adds native speech-to-speech support. 1.68s end-to-end latency, 123 tok/s generation throughput, 1.52x faster than mlx-audio on a single M4 Max.
 DEVELOPERS
DEVELOPERSMarch 13, 2026
MetalRT adds VLM support and wins every decode benchmark. 279 tok/s vision decode, 92ms time-to-output, 1.22x faster than mlx-vlm across all resolutions on a single M4 Max.
March 13, 2026
A deep-dive into how PickleRite — a pickleball performance tracker — runs a specialized LLM entirely on-device using RunAnywhere SDK. Zero cloud costs, full offline support, complete privacy.
 DEVELOPERS
DEVELOPERSMarch 9, 2026
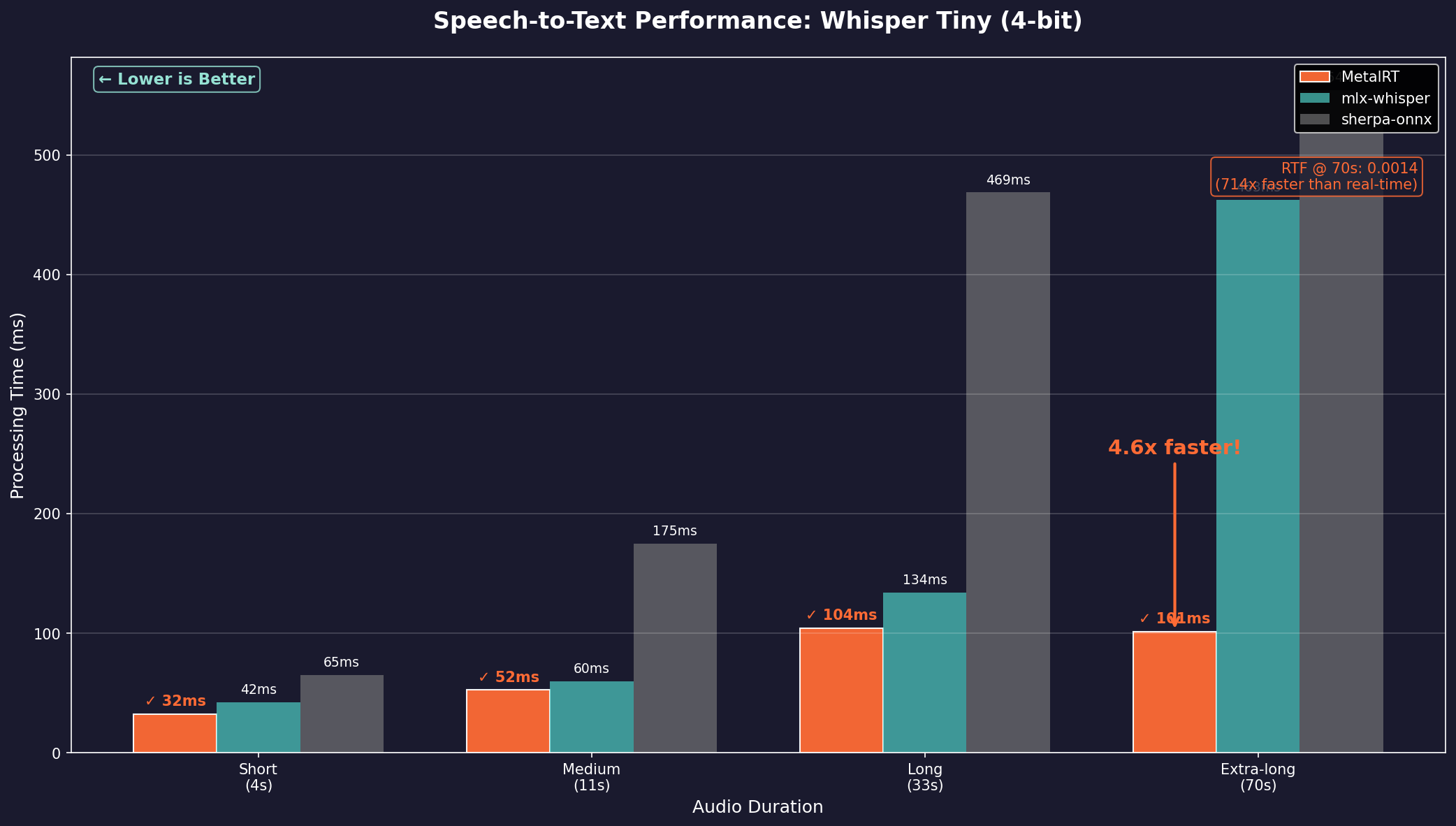
MetalRT becomes the first inference engine to handle LLMs, Speech-to-Text, and Text-to-Speech on Apple Silicon. 101ms to transcribe 70 seconds of audio. 178ms to synthesize speech. 4.6x faster than Apple MLX.
 DEVELOPERS
DEVELOPERSMarch 3, 2026
MetalRT delivers 658 tok/s decode and 6.6ms time-to-first-token, winning decode on 3 of 4 models we tested on a single M4 Max.
 DEVELOPERS
DEVELOPERSFebruary 24, 2026
We added hybrid retrieval (BM25 + vector search) to our on-device voice pipeline. Retrieval adds less than 4ms. The real cost is LLM prefill — but word-level flushing absorbs it. Sub-200ms first-audio on 5,016 chunks with zero cloud dependencies.
 DEVELOPERS
DEVELOPERSFebruary 22, 2026
FastVoice achieves 63ms first-audio latency — well under the 200ms perceptual threshold — by composing STT, LLM, and TTS into a single C++ pipeline on Apple Silicon. No cloud. No network. Just speed.
 DEVELOPERS
DEVELOPERSFebruary 21, 2026
No server. No API key. No internet. Just a phone doing things on its own.
 DEVELOPERS
DEVELOPERSFebruary 19, 2026
And the rabbit hole that taught me more about Android internals than 3 years of app development.
 DEVELOPERS
DEVELOPERSFebruary 9, 2026
Automate web tasks with natural language using a Chrome extension powered by on-device AI. No API keys, no data leaving your browser, complete privacy.
RunAnywhere
On-device AI inference research and infrastructure. Building the fastest engines for the hardware you already own.
Research
Company
Legal