MetalRT: The First Complete AI Inference Engine for Apple Silicon. Now with Speech.
 DEVELOPERS
DEVELOPERSLast week, we shipped the fastest LLM decode engine for Apple Silicon. 658 tok/s on a single M4 Max, 1.67x faster than llama.cpp.
Today, MetalRT becomes the first inference engine to handle all three AI modalities on Apple Silicon: LLMs, Speech-to-Text, and Text-to-Speech.
We benchmarked Whisper STT and Kokoro TTS against every major engine. MetalRT won.
101ms to transcribe 70 seconds of audio. 178ms to synthesize speech. 4.6x faster than Apple's MLX.
Setup
| Engine | Type | Notes |
|---|---|---|
| MetalRT | Native | Complete AI inference engine (LLM + STT + TTS) |
| mlx-whisper | MLX | Apple's official framework (pip install mlx-whisper) |
| mlx-audio | MLX | Apple's TTS framework (pip install mlx-audio) |
| sherpa-onnx | ONNX | Cross-platform baseline (pip install sherpa-onnx) |
- Hardware: Apple M4 Max, 64GB unified memory, macOS 26.3
- Models: Whisper Tiny (4-bit), Kokoro-82M
- Runs: 10 per engine, best reported
- Fairness: Identical inputs across all engines
Speech-to-Text Performance
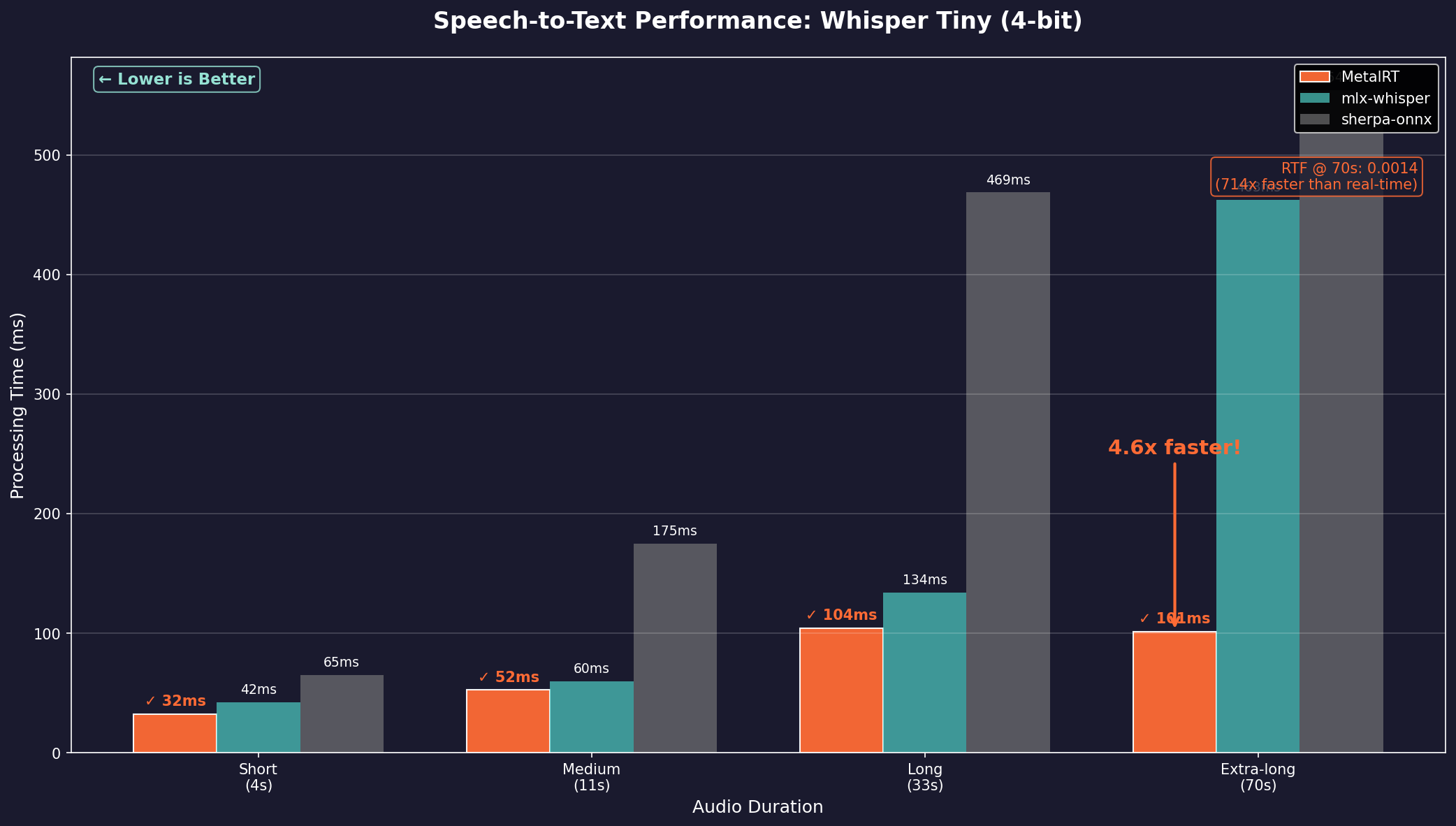
We tested Whisper across four audio lengths. MetalRT won every single one.
Whisper Tiny (4-bit)
Lower latency is better
| Audio Duration | MetalRT | mlx-whisper | sherpa-onnx | Winner |
|---|---|---|---|---|
| Short (4s) | 31.9ms | 42.1ms | 64.9ms | MetalRT |
| Medium (11s) | 52.3ms | 59.6ms | 175ms | MetalRT |
| Long (33s) | 104ms | 134ms | 469ms | MetalRT |
| Extra-long (70s) | 101ms | 463ms | 554ms | MetalRT |
The 70-second result isn't a typo. MetalRT transcribes over a minute of audio in 101 milliseconds.
Real-Time Factor: 0.0014 (lower is better). That's 714x faster than real-time.

Text-to-Speech Performance
For TTS, we tested Kokoro-82M across typical voice assistant response lengths.
Kokoro-82M Results
Lower synthesis time is better
| Text Length | MetalRT | mlx-audio | sherpa-onnx | Winner |
|---|---|---|---|---|
| 4 words | 178ms | 493ms | 504ms | MetalRT |
| 10 words | 230ms | 522ms | 723ms | MetalRT |
| 18 words | 381ms | 600ms | 1,395ms | MetalRT |
| 36 words | 604ms | 706ms | 2,115ms | MetalRT |
MetalRT is 2.8x faster than mlx-audio on short phrases, exactly what voice assistants need.

MetalRT vs The Competition
Speed Advantages
Higher speedup is better

Speech-to-Text (70s audio):
- 4.6x faster than mlx-whisper
- 5.5x faster than sherpa-onnx
Text-to-Speech (4 words):
- 2.8x faster than mlx-audio
- 2.8x faster than sherpa-onnx
Head-to-Head with Apple MLX
Lower latency is better

MetalRT consistently outperforms Apple's MLX framework across both STT and TTS workloads, delivering the fastest on-device inference available for Apple Silicon.
What This Enables
Real-Time Transcription
- 1-hour podcast: ~5 seconds to process
- 3-hour meeting: ~15 seconds
- Live captioning: Zero perceptible delay
Voice Interfaces
- Medical transcription with complete privacy
- Accessibility tools that respond instantly
- Voice AI in secure environments
- Real-time translation without cloud latency
Edge Deployment
- Aircraft systems
- IoT devices
- Offline environments
- High-security facilities
The Numbers That Matter
STT Performance:
- 101ms for 70 seconds of audio (lower is better)
- 714x faster than real-time (higher is better)
- 4.6x speedup vs mlx-whisper (higher is better)
TTS Performance:
- 178ms for typical responses (lower is better)
- 2.8x speedup vs mlx-audio (higher is better)
- Sub-400ms for most use cases
Quality:
- Identical output quality across all engines
- The model is the same
- The speed is not
Summary
Last week, we made LLMs faster. Today, we're making speech faster too.
MetalRT is now the first and only inference engine to accelerate all three AI modalities on Apple Silicon:
- Language Models - Breaking speed records for text generation
- Speech Recognition - Processing hours of audio in seconds
- Voice Synthesis - Real-time responses that feel instant
We didn't just port models to Metal. We reimagined how inference should work on Apple Silicon. The result? Consistently faster performance than Apple's own MLX framework across every workload we tested.
No cloud dependencies. No privacy compromises. No waiting.
The future of AI isn't in data centers. It's running at native speed on the device in front of you.
Benchmarked on Apple M4 Max, 64GB RAM, macOS 26.3. Models: Whisper Tiny (4-bit), Kokoro-82M. 10 runs, best reported. MetalRT: complete inference engine for LLM, STT, and TTS. mlx-whisper/mlx-audio use Apple's MLX framework. sherpa-onnx uses CPU (4 threads).


