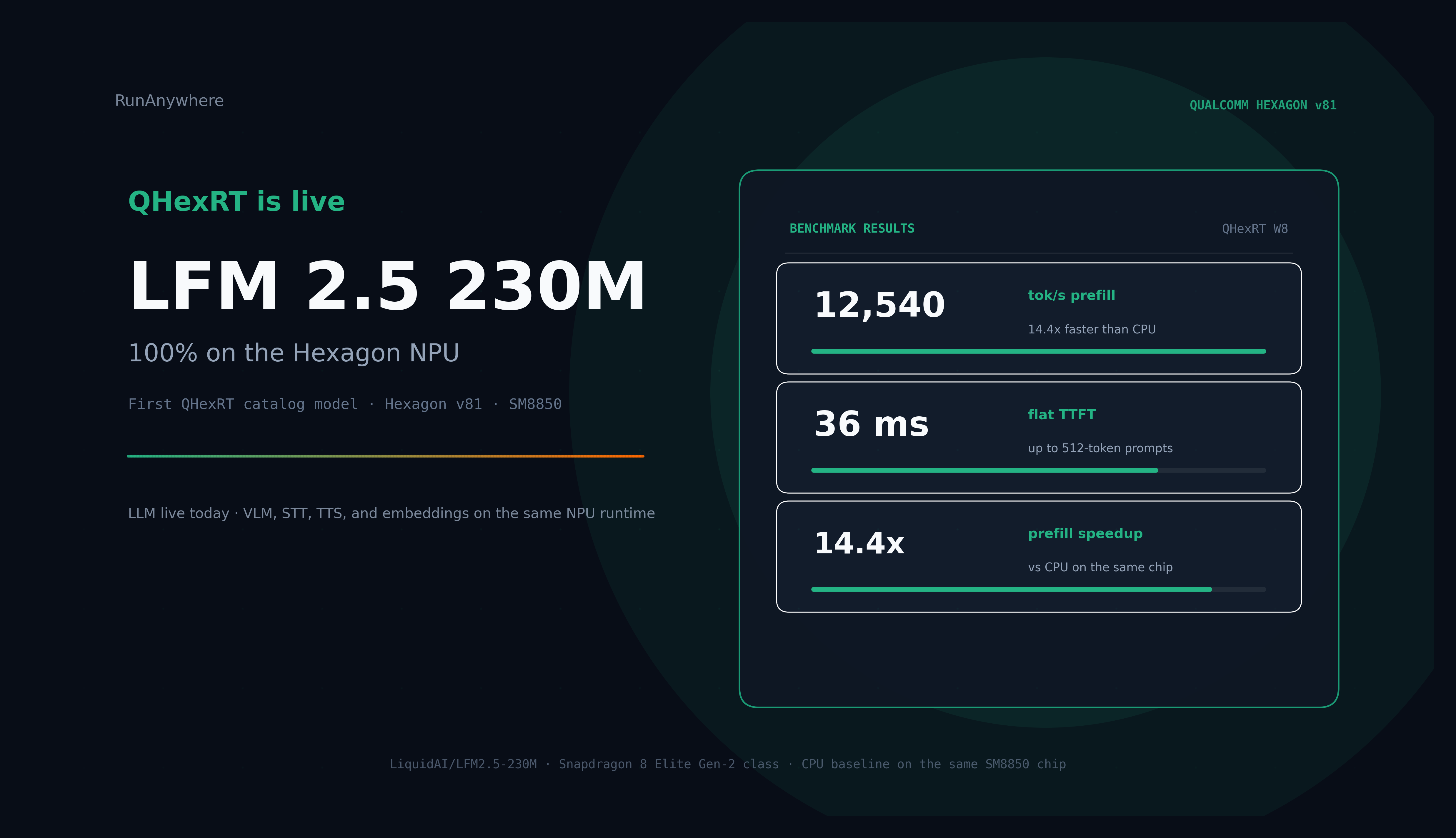
QHexRT
QHexRTJuly 19, 2026
We Put a 27B Model in Your Pocket: PrismML Bonsai 1-bit on iPhone, Android, and Mac
Run a 27 billion parameter LLM on your phone. PrismML's 1-bit Bonsai reasoning models are live in the RunAnywhere apps on iOS, Android, and macOS, including the first true 1-bit model ever to run on any NPU.