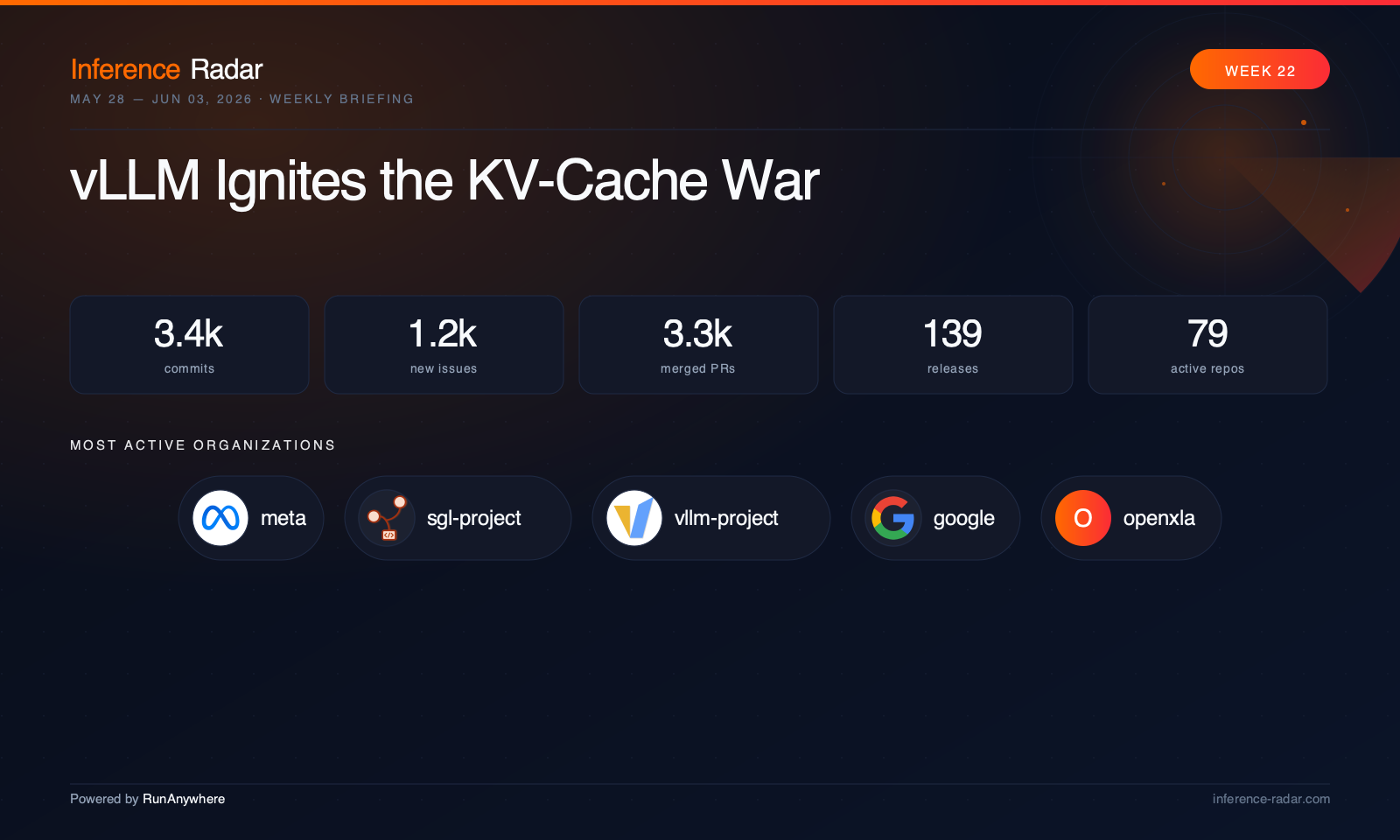

TL;DR
-
Serving engines became cache managers: vLLM, SGLang, TensorRT-LLM, ai-dynamo, and LocalAI all pushed KV routing, KV offload, disaggregated serving, or cache-aware scheduling into more production-facing paths.1
-
GGUF standardized around upstream llama-server: Ollama moved GGUF inference fully onto upstream llama-server while llama.cpp expanded model, backend, server, and multimodal coverage.2
-
Edge inference got more serious: LiteRT-LM, ExecuTorch, TensorRT Edge-LLM, sherpa-onnx, FluidAudio, MNN, and Cactus all advanced mobile, NPU, speech, and local OpenAI-compatible serving paths.3
-
Low precision fragmented but accelerated: ROCm AITER/ATOM, TensorRT-LLM, vLLM, OpenVINO, Intel Neural Compressor, and TileLang all moved FP8, NVFP4, MXFP4, W4A16, or low-bit kernels closer to deployment.
-
API safety moved up the stack: Triton Inference Server, Open WebUI, LiteLLM, ONNX Runtime, and LocalAI hardened OpenAI-compatible endpoints, MCP/OAuth paths, passthrough routes, and request boundaries.4
This Week in Inference
The headline was the absence of a major new open-weight frontier launch during the window; the action instead came from runtimes absorbing recent model families and making them cheaper to serve. Hugging Face added Ideogram 4, Cosmos 3 Omni, Anima, Sapiens2, DeepSeek-OCR-2, Mellum v2, and Gemma4-related support across Transformers and Diffusers, while CTranslate2 added Google T5Gemma2 and SGLang added Command A Plus support for Cohere’s large MoE direction. The market read is clear: the model layer is still moving, but most competitive pressure this week was in model enablement, not model announcement.
The technical center of gravity was memory. vLLM advanced KV-cache offload, shared KV abstractions, MTP speculative decoding, and DeepSeek V4/MoE paths; SGLang pushed HiCache, Mooncake, SWA-aware cache policy, and disaggregated serving; TensorRT-LLM continued KV/disaggregated serving and VisualGen work; ai-dynamo shipped multimodal-aware KV routing and standalone KV indexing. Research and implementation are converging on the same thesis: long-context and MoE serving are fundamentally memory-placement problems, not just matmul problems.
Hardware pressure showed up as code, not just press releases. NVIDIA’s stack shipped across TensorRT, TensorRT-LLM, and TensorRT Edge-LLM; ROCm pushed AITER/ATOM kernels into DeepSeek, Qwen, GLM, and benchmark-serving paths; Google’s LiteRT and XNNPACK improved quantized kernels and mobile runtime safety; Meta’s ExecuTorch expanded Arm, VGF, Ethos-U, NXP, Qualcomm, MLX, and Vulkan backends. Outside GitHub, Groq’s reported fundraising and Nebius’s Eigen AI acquisition underscored the same strategic point: inference software and scheduling layers are now acquisition-grade infrastructure, not glue code.
Top Stories
vLLM turns the serving engine into a memory hierarchy
vLLM’s week centered on DeepSeek V4, MoE, speculative decoding, MRV2, KV-cache offload, and stable ABI work, making the project less a simple OpenAI-compatible server and more a full inference operating system. The release also reflects how fast the serving frontier is moving: low precision, cache placement, and speculative execution are now first-class scheduling concerns in vLLM.1
The Gaudi plugin followed the same churn by aligning with upstream changes, fixing W4A16 MoE loading, improving MiniMax and GPT-OSS MXFP4 behavior, and removing an insecure unused dependency. That matters because hardware-specific plugins increasingly need to track upstream serving internals in near-real time, as shown by vLLM-Gaudi.5
Ollama makes upstream llama-server the GGUF runtime
Ollama removed its CGO GGML engines and standardized GGUF execution on upstream llama-server, leaving MLX as the safetensors path. That is a major architectural simplification for local inference, but it also created immediate packaging, Windows, ROCm, process-cleanup, and Gemma 4 stabilization work in Ollama.2
The move also reinforces llama.cpp’s role as the local-runtime substrate. In the same week, llama.cpp expanded DeepSeek, Gemma, Qwen, StepFun, EXAONE, Granite, Vulkan, CUDA, HIP, Metal, OpenCL, SYCL, Hexagon, and server-side behavior across a very high-volume release cadence in llama.cpp.6
Edge stacks are converging on real serving, not demos
Google’s LiteRT-LM added OpenAI-compatible serving, Android demo-agent support, macOS Swift package support, LoRA APIs, multimodal preprocessing, and GPU/NPU instrumentation. That moves LiteRT-LM closer to being an application-facing local inference layer instead of a model execution sample.3
Meta’s ExecuTorch pushed backend coverage across Arm, VGF, TOSA, Ethos-U, NXP, Qualcomm, MLX, Vulkan, XNNPACK, and Android while shipping a patch release. The release confirms that ExecuTorch is increasingly a bridge between PyTorch export semantics and real device constraints.7
The speech stack heated up across mobile, local, and server
FluidAudio added CoreML SenseVoiceSmall and Paraformer-large zh, with production fixes for offline mode, iOS storage, and model downloads. In parallel, sherpa-onnx added an end-to-end Qualcomm QNN streaming Zipformer Transducer path with export automation and Android demo support in sherpa-onnx.8
The demand signal was broader than those two projects. LocalAI added Parakeet and CrispASR backend work, RunAnywhere added hybrid local/cloud STT routing, Triton users requested FunASR/SenseVoice examples, and oobabooga users asked for faster multilingual STT support through text-generation-webui.9
ONNX and Triton hardened the enterprise boundary
ONNX added LinearAttention and CausalConvWithState for modern hybrid LLM architectures, while ONNX Runtime pushed WebGPU, Gemma 4 decoder support, quantized LLM execution, QMoE, MLAS LUT GEMM, and security fixes. The ONNX/ORT coordination around Conv shape-inference safety shows how enterprise inference stacks increasingly require upstream schema fixes, not downstream patches, in ONNX.10
Triton shipped an OpenAI frontend request-size limit before JSON parsing, added Python backend archive traversal regression coverage, and removed Windows server build support. That combination makes Triton Inference Server look less like a model server release and more like a production boundary-hardening release.4
Deeper Dive
Everything below is for readers who want the full picture. Feel free to scroll.
Code Changes by Category
Cloud & Datacenter Serving
vLLM had one of the week’s highest-impact serving updates: MRV2, MTP speculation, DeepSeek V4/MoE, KV-cache offload, stable ABI work, ROCm/RDNA paths, Blackwell cubins, Rust frontend routes, and Responses API correctness all moved together in vLLM.1
SGLang had an infrastructure-heavy week across AMD FP4, CUDA graph internals, HiCache, Mooncake, SWA cache policy, disaggregated KV, diffusion serving, MLX/XPU/CPU/NPU paths, and multimodal support in SGLang.11
NVIDIA’s TensorRT stack shipped core TensorRT OSS, TensorRT Edge-LLM, and TensorRT-LLM release-candidate work covering VisualGen, AutoDeploy, KV/disaggregated serving, Qwen-Image, DeepSeek paths, Blackwell CuTe DSL attention, and Jetson/Thor validation in TensorRT-LLM.12
ai-dynamo shipped a feature release centered on multimodal serving, TensorRT-LLM text-to-image, audio/video streaming protocols, multimodal-aware KV routing, branch-sharded standalone KV indexing, Kubernetes APIs, and inter-pod GPU Memory Service productization in Dynamo.13
Ray focused on production hardening across Ray Data, Serve/LLM, HAProxy routing, direct streaming, LLM test flakes, GCS restart behavior, platform events, and vLLM dependency updates in Ray.14
LocalAI had a busy release train around prefix-cache-aware distributed routing, NATS security, Parakeet ASR, CrispASR, OpenAI-compatible tool-call fixes, reasoning controls, SSRF hardening, and frontend bundle reductions in LocalAI.15
LiteLLM heavily expanded MCP/A2A agent routing, passthrough security, OAuth metadata handling, A2A discovery, provider compatibility, budget/rate-limit paths, guardrails, OpenTelemetry, and UI/auth fixes in LiteLLM.16
Triton Inference Server shipped a production-focused release and then added OpenAI request-size limits, path-traversal regression coverage for Python backend execution environments, and Windows server-build removal in Triton.17
Local LLM Runtimes
llama.cpp expanded DeepSeek V3.2, Gemma 4 unified multimodal fixes, Qwen MTP behavior, speculative decoding, KV-cache reductions, Vulkan/OpenCL/SYCL/CUDA/HIP/Metal/Hexagon backends, and server UI/API behavior in llama.cpp.6
Ollama’s central change was the full GGUF move to upstream llama-server, followed by Windows process cleanup, ROCm fixes, Gemma 4 support, projector handling, embeddings normalization, Codex/Qwen Code/Cline/opencode launch integrations, and packaging fallout in Ollama.18
Mozilla’s llamafile shipped a hotfix after a Windows GPU-probing regression, added safer backend probing with signal guards and CPU fallback, refreshed llama.cpp, restored the web UI bundle path, modernized Diffusionfile, and improved release automation in llamafile.19
oobabooga refreshed llama.cpp install profiles across CPU, AMD, Apple, CUDA, Vulkan, and ik_llama variants while users reported a source-built Docker llama-server shared-library failure in text-generation-webui.20
exo replaced libp2p with Zenoh, renamed its Rust/Python bindings, split energy accounting into prefill and generation phases, improved macOS installation paths, and opened follow-up Zenoh storage and sharding work in exo.21
Cactus added a local OpenAI-compatible server, text/image/audio embeddings, v2 NPU support, Gemma4 work, JAX/Flax transpilation, and better test failure accounting in Cactus.22
Apple Silicon & MLX Ecosystem
Apple’s MLX stack hardened iOS Metal defaults, macOS workflow tooling, CUDA reductions, shapeless compile inference, Swift chat/session/tool-call behavior, Gemma4Text KV-cache fixes, Qwen2.5-VL parity, and Swift package release polish in MLX Swift.23
Blaizzy’s MLX projects expanded audio/VLM coverage with Irodori-TTS, Granite Speech, Miso TTS prep, Gemma 4 Unified, LocateAnything, Cohere2 MoE, Step-3.7 Flash, FLUX.2, Qwen3 Omni placeholders, and OpenAI-compatible audio/VLM server fixes in mlx-vlm.24
jundot’s oMLX moved to a native Swift macOS app, added a major chat overhaul, bundled structured-output support, tuned Memory Guard regressions, wired TurboQuant KV-cache compression, and fixed Claude Code/system-role compatibility in oMLX.25
vllm-mlx added a multi-slot system-KV LRU cache, /v1/status metrics parity, system-prompt canonicalization, stricter response_format, ordered multimodal reconstruction, Gemma 4 attention compatibility, and Qwen tool-call parser cleanup in vllm-mlx.26
try-mirai’s Lalamo and Uzu aligned Gemma4 shared-KV behavior, removed RoPE tables, tightened dtype rules, optimized Qwen3.5/DeltaNet/Mamba paths, and improved Apple-device kernels and benchmarking in Lalamo.27
Mobile & Edge Frameworks
Google’s LiteRT-LM release added Android demo-agent support, OpenAI-compatible serving, macOS Swift package support, LoRA tooling, multimodal preprocessing, and GPU/NPU instrumentation in LiteRT-LM.3
Meta’s ExecuTorch expanded Arm/VGF/TOSA, Ethos-U, ANE LoRA, MLX, Android Kotlin, NXP, Qualcomm, ESP32, Vulkan, XNNPACK mmap weights, runtime validation, and backend CI while shipping a patch release in ExecuTorch.7
Alibaba’s MNN fixed Qwen3-VL repeated-output failures, LinearAttention prefix-cache rollback behavior, DeepStack dtype export mismatches, Hy-MT2/Hunyuan support, ARM low-bit GEMM, OpenCL int4 paths, CUDA Windows support, and RVV vectorization in MNN.28
sherpa-onnx added Qualcomm QNN streaming Zipformer Transducer recognition, export automation, Android demo/APK support, mobile ONNX Runtime override paths, and X-ASR upload logic in sherpa-onnx.29
FluidAudio added CoreML SenseVoiceSmall, Paraformer-large zh, stricter offline mode, durable iOS model storage, Supertonic voice enums, PocketTTS stride handling, diarization embeddings, and streaming timestamp support in FluidAudio.30
RunAnywhere added an STT-only hybrid router that cascades between local sherpa-onnx and cloud Sarvam using eligibility filters, confidence thresholds, JNI/Kotlin APIs, and Android asset updates in runanywhere-sdks.31
Tencent’s ncnn accelerated ARM RotaryEmbed with fp32/fp16/BF16 NEON paths, expanded OOM tests across architectures, cleaned MIPS/LoongArch GEMM paths, and continued Vulkan/RISC-V/x86 performance work in ncnn.32
Qualcomm’s AI Hub repos refreshed model scorecards, LLM validation, QDC reliability, app build automation, Docker bundling, MiniLM metadata, and Qwen3-TTS NPU collaboration requests in ai-hub-models.33
Compilers, Runtimes & Graph Engines
Apache TVM moved structural APIs and JSON serialization onto tvm-ffi, improved TIRx/Blackwell-oriented codegen, expanded Relax TFLite/StableHLO frontend coverage, and modernized wheel publishing in TVM.34
OpenXLA added FP6 primitive types, switched CUDA allocation toward VMM, added VMM map/unmap APIs, refactored GPU command-buffer/thunk paths, improved CPU/oneDNN correctness, and tightened export/sharding compatibility in XLA.35
Triton language tightened TMA store-wait semantics, advanced Blackwell/Gluon enablement, fixed AMD backend correctness, cleaned FPSAN/MMAv5 work, and improved profiling/build reliability in Triton.36
TileLang added RDNA4/Wave32 ROCm support, HIP vector math fixes, stochastic FP8/FP4 casts, TMA store-wait support, ragged SIMT guard handling, layout/reduction fixes, and CuTeDSL internals cleanup in TileLang.37
ONNX added LinearAttention, CausalConvWithState, low-precision Range support, Conv shape-inference safety fixes, validation hardening, and roadmap/build hygiene in ONNX.38
ONNX Runtime pushed WebGPU quantized LLM fusions, Gemma 4 decoder support, CUDA/CPU quantized kernels, QMoE, MLAS LUT GEMM, plugin EP validation, CoreML ops, and model-reference hardening in ONNX Runtime.39
OpenVINO shipped a coordinated release while advancing GPU SYCL runtime work, NPU/NPUW executors and KV-cache paths, CPU tree attention, ARM/RISC-V emitters, GenAI benchmark metrics, and NNCF release pins in OpenVINO.40
Models, Quantization & Optimization
Hugging Face added Ideogram 4, Cosmos 3 Omni, Anima, AutoPipelineForText2Audio, Sapiens2, DeepSeek-OCR-2, Mellum v2, Gemma4 work, Candle SIMD/Metal speedups, Neuron backend support, and security/correctness fixes in Transformers.41
Intel Neural Compressor shipped experimental JAX support, FP8 Keras/JAX quantization, FP8 KV-cache and Attention static quantization, Gemma3/ViT examples, and non-mutating JAX quantization in Neural Compressor.42
ROCm AITER and ATOM pushed MXFP4/MXFP8, MoE, MLA/FMHA, gfx950/RDNA kernels, vLLM/SGLang integration, DeepSeek V4/V4-Flash, Qwen/GLM hot paths, and benchmark gates in AITER.43
LMDeploy added Qwen3-Omni, Qwen3.5 MTP scaling, FP8 KV-cache quantization, raw logprob output, guided-decoding event-loop fixes, health-status plumbing, and TurboMind fixes in LMDeploy.44
DeepSpeed focused on ZeRO/DeepCompile correctness, gathered-storage lifetime fixes, deterministic all-gather scheduling, multi-backward gradient reduction coalescing, torch.func compatibility, and release-adjacent PyPI repair work in DeepSpeed.45
CTranslate2 added Google T5Gemma2 support and cut CI time by moving ARM builds away from emulation and caching Windows dependencies in CTranslate2.46
Other Notable Changes
Open WebUI shipped a large release centered on security hardening, RAG/search, OAuth/MCP, Valkey vector support, per-chat skills toggles, frontend stability, and the companion knowledge-base sync direction in Open WebUI.47
osaurus shipped a rapid macOS-agent release train with Gemma 4 vMLX proofing, conservative model-cache matrices, MiniMax/AtlasCloud providers, stricter relay health validation, sandbox/file tooling, and localization polish in Osaurus.48
Zetic shipped an iOS framework release focused on CoreML runtime stabilization in ZeticMLangeiOS.49
Community Pulse
The hottest community theme was production fallout from runtime consolidation: Ollama users reported missing llama-server packaging, Gemma4 crashes, VRAM/KV retention, Codex integration breakage, and AMD/iGPU behavior after the GGUF runtime transition in Ollama.50
Speech became a cross-ecosystem request pattern, with FunASR/SenseVoice or faster local STT requests appearing in Triton, oobabooga, BentoML, RunAnywhere, FluidAudio, sherpa-onnx, and Cactus issue trackers through Triton.51
DeepSeek users surfaced API compatibility, thinking-mode tool-choice constraints, and reasoning-safety reports even without code changes in DeepSeek-V3.52
SGLang, vLLM, ROCm, TensorRT-LLM, and TileLang all showed intense issue traffic around DeepSeek V4/V4-Flash, MXFP4, MLA, HiCache/KV geometry, CUDA graph capture, and low-precision MoE behavior through SGLang.53
Open WebUI’s release immediately generated regression reports around web search, RAG embedding engine configuration, OAuth pending-page logout, eager skill injection, and knowledge-base rename behavior in Open WebUI.54
Community Debates
llama.cpp maintainers pushed back on several feature proposals where the implementation looked too hacky, too client-specific, or too AI-generated, including server checkpointing before user turns and SSE keepalives without root-cause analysis in llama.cpp.55
Ollama closed TurboQuant KV-cache compression after build failures, Metal issues, ROCm throughput concerns, Gemma 4 fallback work, and quality regressions, showing that KV compression is still a quality/performance tradeoff rather than a drop-in win in Ollama.56
Open WebUI closed several large or architecture-blurring proposals, including a shared-chats dashboard and Google Drive sync, with maintainers steering contributors toward smaller, tested PRs and the new external knowledge-base sync architecture in Open WebUI.57
ONNX merged LinearAttention but still exposed process tension around operator RFC timing, scope, and whether the new op can express some gated-delta architectures without Scan in ONNX.58
Triton language’s TMA store-wait changes showed a classic compiler debate: correctness for global visibility landed first, then performance concerns forced read-only wait paths and default/documentation cleanup in Triton.59
Hugging Face Transformers had visible maintainer friction around overlapping and agent-generated PRs, including a context-parallelism proposal labeled as low-quality agent work in Transformers.60
Worth Watching
KV-cache hierarchy is becoming the defining abstraction across cloud and local inference, with vLLM offload, SGLang HiCache, ai-dynamo routing, TensorRT-LLM disaggregation, LocalAI prefix routing, and Cactus KeyDiff work all pointing the same way through vLLM.61
FP8/NVFP4/MXFP4 are becoming the datacenter low-precision dialects, while GGUF/Q4 and MLX/TurboQuant-style paths dominate local and Apple Silicon workflows through ROCm AITER.62
Speech is becoming the next edge-inference battleground, with CoreML ASR, Qualcomm QNN ASR, local/cloud STT routing, and repeated SenseVoice/FunASR requests converging through FluidAudio.63
OpenAI-compatible APIs are now security boundaries, not convenience wrappers, as Triton, LocalAI, Open WebUI, LiteLLM, vLLM, and Ollama all touched request limits, tool-call parsing, passthrough authorization, or system-role compatibility through Triton.4
WebGPU is quietly becoming more than a browser demo path, with ONNX Runtime’s standalone WebGPU plugin and quantized LLM fusions pointing to a deployable client-side inference layer in ONNX Runtime.64
Major Releases
The canonical version list for the week.
vLLM Project shipped vLLM v0.22.0 and vLLM-Gaudi v0.21.0, with core work focused on DeepSeek V4, NVFP4 fused MoE, MTP speculative decoding, KV offload, MRV2, stable ABI, and ROCm/Blackwell/Gaudi parity. The most impactful change was the move toward a memory-hierarchy-oriented serving engine rather than a simple batching server. vLLM release notes.1
NVIDIA shipped TensorRT v11.0, TensorRT Edge-LLM v0.8.0, and TensorRT-LLM v1.3.0rc17, spanning core parser/plugin updates, edge checkpoint export, JetPack/Jetson/Thor validation, VisualGen, AutoDeploy, KV serving, and multimodal fixes. The dominant theme was end-to-end modernization from low-level TensorRT plugins to edge deployment and cloud LLM serving. TensorRT-LLM release notes.12
Ollama shipped v0.30.2 → v0.30.4, all orbiting the transition to upstream llama-server, launch-tool integrations, Gemma 4 support, Windows cleanup, and post-migration stabilization. The most important release was the latest patch, which updated llama.cpp and fixed lingering Windows llama-server processes while calling out a known Gemma 4 crash. Latest release.18
ggml shipped an unusually large llama.cpp build train plus whisper.cpp v1.8.5 and v1.8.6, with llama.cpp adding model/backend/server coverage and whisper.cpp cleaning up licensing, packaging, and ggml syncs. The standout change was llama.cpp’s continued expansion across DeepSeek, Gemma, Qwen, Vulkan, CUDA/HIP, Metal, SYCL, OpenCL, and Hexagon. llama.cpp latest release.6
Google AI Edge shipped LiteRT-LM v0.13.0 and v0.13.1, focused on Android demo-agent support, OpenAI-compatible serving, macOS Swift package support, LoRA tooling, multimodal preprocessing, and bug fixes. The key change was turning LiteRT-LM into a more application-facing local inference layer. LiteRT-LM release notes.3
Meta / PyTorch shipped ExecuTorch v1.3.1, a broad patch release after the prior Maven-only release. The release emphasized embedded/mobile/GPU backend coverage across Arm, Cortex-M, VGF, NXP, Qualcomm, CUDA, Metal, MLX, Vulkan, XNNPACK, and broader LLM/multimodal support. ExecuTorch release notes.7
OpenVINO Toolkit shipped OpenVINO 2026.2.0, OpenVINO GenAI 2026.2.0.0, and NNCF v3.2.0, covering expanded GenAI model coverage, product-version infrastructure, benchmarking updates, and weight-node ignore support. The release train’s dominant theme was GenAI readiness across GPU, NPU, CPU, and compression tooling. OpenVINO release notes.40
Microsoft ONNX Runtime shipped plugin-ep-webgpu/v0.1.0, the first standalone WebGPU Execution Provider plugin release. The significance is packaging: WebGPU execution can now register with an existing ONNX Runtime installation as a separate plugin..64
Triton Inference Server shipped v2.69.0, corresponding to the NGC 26.05 container. The release was followed by main-branch updates and hardening work around OpenAI request limits, Python backend archive traversal tests, and Windows server build removal..17
Hugging Face shipped Transformers v5.10.1 after the previous release was yanked due to a corrupted branch. The release highlights included Gemma4 unified and MTP work alongside the week’s broader model additions..41
ai-dynamo shipped v1.2.0 and v1.3.0-cosmos3-dev.1, with the stable release focused on multimodal serving, TensorRT-LLM text-to-image, streaming protocols, multimodal-aware KV routing, standalone KV indexing, Kubernetes APIs, and GPU Memory Service productization. The prerelease explored Cosmos3 evaluation on Dynamo vLLM-Omni. v1.2.0 release notes.13
BerriAI shipped multiple LiteLLM releases from v1.84.4 through v1.88.0-rc.1, with release notes centered on Docker image signature verification guidance while code activity pushed MCP/A2A, passthrough, budgets, provider support, and guardrails. The most important stable release was v1.87.0..16
Apple MLX shipped mlx-swift 0.31.4, focused on doc-comment CI verification, QuantizedLinear fixes for non-affine quantization modes, more compile overloads, and missing function additions. The release complemented broader MLX runtime and Swift LLM work..23
Blaizzy shipped mlx-vlm v0.6.0 and v0.6.1, with a major model-surface expansion across Gemma 4, LocateAnything, Cohere2 MoE, Step-3.7 Flash, FLUX.2, server metrics, streaming, cache recovery, and compatibility fixes. The latest patch added backend linear-spec handling and several model fixes. Latest release.24
FluidInference shipped FluidAudio v0.14.8, with notes highlighting download fixes for non-baseline model paths, word-boost improvements, Parakeet language/Greek support, and EoU streaming timestamp support. The release landed alongside major SenseVoiceSmall and Paraformer-large zh CoreML work..30
Intel shipped Neural Compressor v3.8, adding experimental JAX support, FP8 Keras/JAX quantization, FP8 KV-cache static quantization, FP8 Attention static quantization, and Gemma3/ViT examples. The standout change was extending Intel’s quantization surface into JAX/Keras FP8 workflows..42
InternLM shipped lmdeploy v0.14.0a1, a prerelease featuring FP8 KV-cache quantization plus TurboMind modeling and CUDA-error-handling improvements. The release packaged a week of Qwen3-Omni, Qwen3.5 MTP, serving optimization, and health-status work..44
Mozilla AI shipped llamafile 0.10.2 and 0.10.3, with the latter hotfixing a Windows GPU-probing crash and improving release automation. The broader release updated llama.cpp, restored web UI embedding, improved GPU diagnostics, and modernized Diffusionfile. Latest release.19
LocalAI shipped v4.3.3 → v4.3.6, with releases focused on llama.cpp updates, TurboQuant compatibility, tool-call streaming fixes, outbound HTTP redirect hardening, and Parakeet ASR support. The latest release best represents the week’s ASR and security direction. Latest release.15
Open WebUI shipped v0.9.6, announcing oikb as an official companion knowledge-base sync tool and adding incremental sync support. The release also landed a broad security, RAG/search, OAuth/MCP, and frontend hardening wave..47
ROCm shipped AITER v0.1.13.post1, AITER v0.1.15-rc0, AMDMIGraphX rocm-7.2.4, and ATOM v0.1.3, spanning MXFP4/MXFP8 kernels, DeepSeek/Kimi/MiniMax paths, MI35x runner verification, dashboards, and plugin validation. The main theme was moving ROCm frontier-model serving from kernels into runtime benchmarks and serving integrations. AITER release notes.43
TensorFlow shipped TensorFlow Serving 2.20.0, a maintenance release with no major features or breaking changes. The surrounding TensorFlow activity focused on XLA/backend fixes, TFLite Micro compression refactors, and security/malformed-input hardening..65
try-mirai shipped lalamo v0.12.0, lalamo v0.12.1, and uzu 0.5.3, with Lalamo centered on Gemma4 shared-KV correctness, dtype discipline, classification tooling, dead-code removal, and hybrid-compression fixes. The Uzu release had limited notes but landed amid major Apple-device runtime and kernel optimization work. Lalamo latest release.27
jundot shipped oMLX v0.4.0rc1, v0.4.0rc2, v0.4.0, and v0.4.1, marking the transition to a native Swift macOS app. The latest release focused on memory-pressure stability, model discovery robustness, managed server lifecycle controls, and macOS app/CLI quality of life. Latest release.25
osaurus-ai shipped 0.19.1 → 0.19.7, a rapid macOS agent release train covering model-browser polish, file/MCP/OAuth hardening, sandbox proofing, relay validation, MiniMax, Step/LFM proofing, context-budget fixes, and LFM tool/cache proof. The latest release is most representative of the runtime-proofing and agent-stability push. Latest release.48
zetic-ai shipped ZeticMLangeiOS 1.8.0, a small iOS framework release focused on stabilizing the CoreML runtime. The release was limited but relevant for mobile CoreML deployment stability..49