QHexRT Is Live: Full-Stack NPU Inference for Qualcomm Hexagon
 DEVELOPERS
DEVELOPERSWe shipped MetalRT for Apple Silicon — the first engine to run LLM, speech, vision, and speech-to-speech in one runtime, entirely on the GPU. Today we're launching QHexRT for Qualcomm: the same bet on the NPU.
QHexRT runs inference 100% on the Hexagon NPU. No Python in the hot path. No CPU fallback during inference. We are building the widest model catalog on any Qualcomm NPU stack, with same-day support for the models the community ships.
No one has shipped a single runtime that covers LLM, VLM, STT, TTS, and embeddings fully on Qualcomm NPUs. MetalRT did it for Apple Silicon. QHexRT does it for Hexagon.
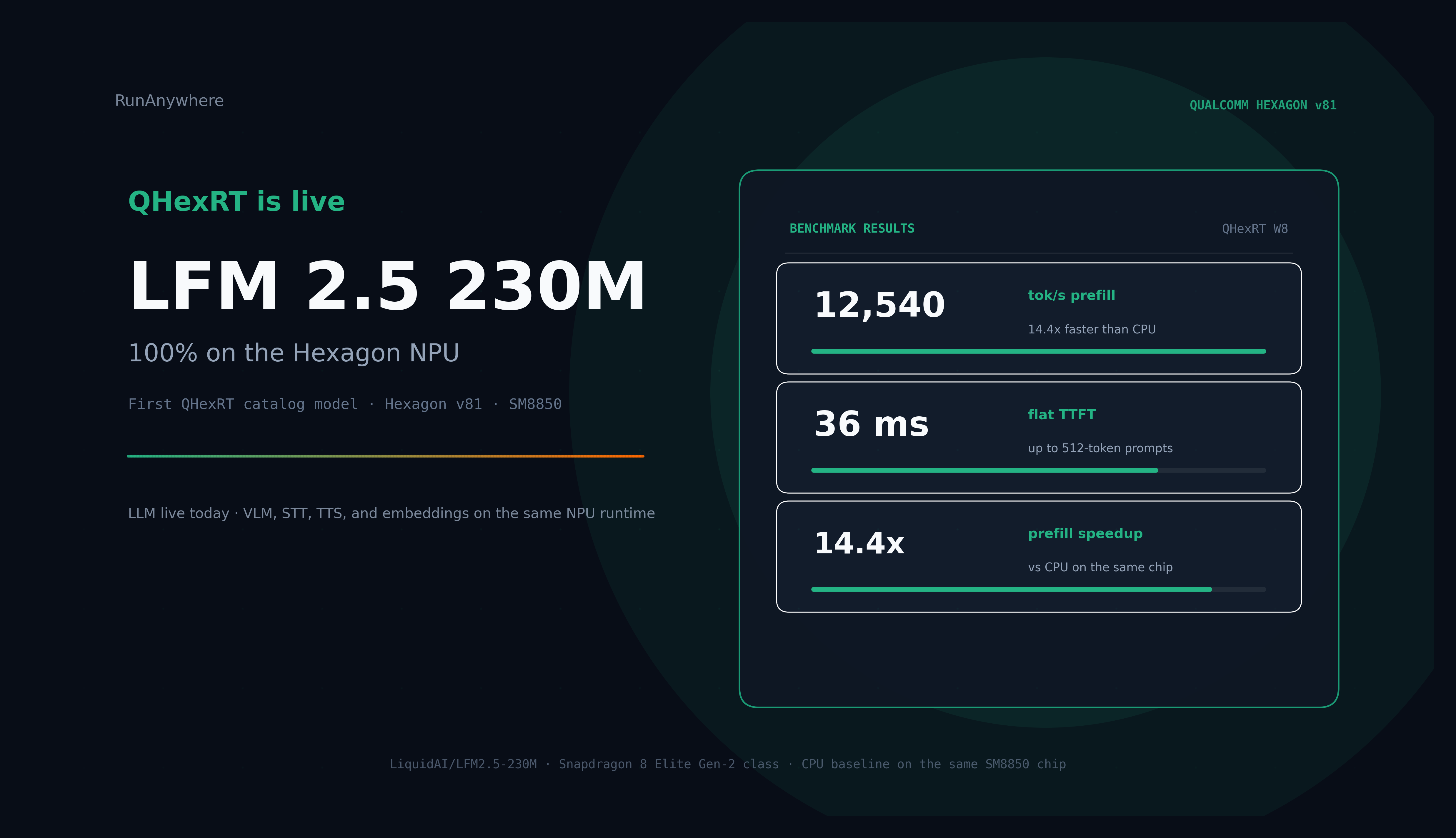
First model: LFM 2.5 230M
LiquidAI released LFM 2.5 230M on June 25, 2026. QHexRT supports it on day one — our first catalog entry. The NPU bundle is on Hugging Face: runanywhere/lfm2_5_230m_HNPU.
Every tensor in the inference path stays on the HTP: decode graph, prefill graph, lm-head, embeddings. Greedy output matches the source model ("The capital of France is" → " Paris.").
All modalities, one NPU runtime
| Modality | Status |
|---|---|
| LLM | Live — LFM 2.5 230M on Hexagon v81 |
| VLM | In development |
| STT | In development |
| TTS | In development |
| Embeddings | In development |
One engine, one deployment model, every modality on the NPU — the same architecture MetalRT proved on Apple Silicon, now on Qualcomm.
The headline numbers (LFM 2.5 230M · Hexagon v81)
Benchmarked on Hexagon v81 (Snapdragon 8 Elite Gen-2, SM8850). We also ran llama.cpp on the CPU of the same chip, same die, same phone. Both stacks produce identical output. The only variable is speed.
- Prefill: 12,540 tok/s on the NPU vs 871 on the CPU (Q8_0). 14.4x faster.
- Time-to-first-token: 36ms flat for any prompt up to 512 tokens. The CPU takes 588ms at 512 tokens.
- Decode: the CPU wins at 250 tok/s vs 172 on the NPU. At 230M params, decode is memory-bandwidth-bound, and the Oryon CPU pulls more usable bandwidth from DDR on this weight set.
- End-to-end: the NPU wins once the prompt exceeds ~1.5x the generation length.
QHexRT's W8 graph matched the HuggingFace fp32 oracle at logits cosine 1.000000. Equal quality, NPU-only inference.
Setup
| Item | Value |
|---|---|
| Device | Qualcomm SM8850 (Snapdragon 8 Elite Gen-2 class) |
| NPU | Hexagon v81 (HTP) |
| CPU | 8-core Oryon (up to ~4.4 GHz) — comparison baseline only |
| Model | LiquidAI/LFM 2.5 230M (229.69M params, hybrid decoder) |
| NPU bundle | runanywhere/lfm2_5_230m_HNPU (v81 context binaries, W8) |
| NPU stack | QHexRT, W8 weight-only (int8 weights, fp16 activations) |
| CPU stack | llama.cpp b1-beac530, Q8_0 + Q4_K_M (comparison only) |
| Fairness | HTP clock pinned to TURBO; CPU governor pinned to performance, all 8 cores |
Run it
Download the v81 NPU bundle from runanywhere/lfm2_5_230m_HNPU. It includes the QNN context binaries (decode, prefill, lm-head), embeddings, tokenizer, and manifest.
1hf download runanywhere/lfm2_5_230m_HNPU --local-dir lfm2_5_230m_HNPU2adb push lfm2_5_230m_HNPU/v81 /data/local/tmp/lfm2303adb shell "cd /data/local/tmp/lfm230 && LD_LIBRARY_PATH=. \4 ./qhx_generate lfm2-5-230m.json libQnnHtp.so libQnnSystem.so . 64 'The capital of France is'"
Stage the QAIRT v81 runtime libs (libQnnHtp.so, libQnnSystem.so, libQnnHtpV81Skel.so/Stub.so) and the qhx_generate tool into the same directory. Context binaries are pinned to Hexagon v81. Contact us for deployment access.
Throughput
| Engine | Prefill (tok/s) | Decode (tok/s) | Decode (ms/tok) | Peak RAM (MB) |
|---|---|---|---|---|
| QHexRT NPU (v81, W8) | 12,540 | 172 | 5.8 | 445 |
| llama.cpp CPU Q8_0 | 871 | 250 | 4.0 | 299 |
| llama.cpp CPU Q4_K_M | 680 | 264 | 3.83 | 209 |
Prefill is where the NPU wins by the widest margin. QHexRT runs it as one batched forward over a padded 512-token window, so the cost stays constant regardless of prompt length.

Figure 1 — Prefill throughput (log scale). QHexRT on Hexagon v81 hits 12,540 tok/s prefill on LFM 2.5 230M. llama.cpp on the same die's Oryon CPU reaches 871 tok/s (Q8_0) and 680 tok/s (Q4_K_M). That is 14.4x and 18.4x faster prefill on the NPU.
Decode on this 230M model is DDR-bandwidth-bound. Larger models shift toward compute-bound decode, where the NPU's HMX units have the advantage.
Time to first token
| Prompt (tokens) | NPU (ms) | CPU Q8_0 (ms) | CPU Q4_K_M (ms) |
|---|---|---|---|
| 16 | 36 | 17 | 26 |
| 128 | 36 | 132 | 188 |
| 512 | 36 | 588 | 753 |

Figure 2 — Time to first token vs prompt length (LFM 2.5 230M). The NPU holds a flat ~36 ms TTFT for any prompt up to 512 tokens. At 512 tokens the NPU delivers its first token 16x sooner than Q8_0 (36 ms vs 588 ms).
The model catalog
LFM 2.5 230M on Hexagon v81 is the first entry. We're adding models as fast as the community ships them — Qwen3, Gemma 3, Phi-4-mini, and other sub-4B models that fit the NPU memory budget, each with the same 100% NPU path.
Next on the roadmap:
- VLM, STT, TTS, embeddings on Hexagon — completing the full multimodal stack on the NPU.
- More LLM models across the widest Qualcomm NPU catalog.
- W4 quantization — roughly halving per-token bytes, projecting ~300–340 tok/s decode on this model class.
- Power metering — tok/s-per-watt vs CPU baseline.
Summary
- QHexRT is live — full-stack NPU inference for Qualcomm Hexagon
- 100% on NPU — no Python, no CPU fallback during inference
- First model: LFM 2.5 230M (runanywhere/lfm2_5_230m_HNPU)
- 12,540 tok/s prefill · 36ms flat TTFT · identical greedy output vs fp32 oracle
- All modalities — LLM live; VLM, STT, TTS, embeddings in development
- Widest model catalog for Qualcomm NPUs, expanding continuously
Contact us for QHexRT deployment access. Download the first model from Hugging Face.
Benchmarked on Qualcomm SM8850 / Hexagon v81. Model: LiquidAI/LFM 2.5 230M. NPU: QHexRT W8 weight-only, QAIRT 2.47.0.260601. CPU comparison: llama.cpp b1-beac530, Q8_0 + Q4_K_M, 8 threads.